AI and Big Data in Healthcare: Towards a More Comprehensive Research Framework for Multimorbidity
J Clin Med. 2021 Feb; 10(4): 766. Published online 2021 Feb 14. doi: 10.3390/jcm10040766
Ljiljana Trtica Majnarić,František Babič, Shane O’Sullivan, and Andreas Holzinger
PMID: 33672914
Multimorbidityをかれこれ2年ほど勉強していますが,こういう時代が近い将来来ると思います。AIやビッグデータのことをそもそもよく知らないのは致命的です。こういうことにも詳しくなければならないということで,データサイエンスの勉強を兼ねてこの論文を読もうと思います。

筆頭著者のLjiljana Trtica Majnarić先生はクロアチアの家庭医療の先生のようです。
https://www.egprn.org/profile/31530c30-94cd-471d-84ea-ad991e85eda4/LJILJANA-MAJNARIC
Abstract
Multimorbidityとは、1人の人間に2つ以上の慢性疾患が共存している状態を指します。そのため、Multimorbidityの患者は、複数の特別なケアを必要とします。しかし、現在の医療システムの組織的プロセスは、単一の疾患に合わせて調整される傾向があるため、実際にはこれらのニーズを満たすことは困難です。Multimorbidity患者の臨床的意思決定や患者ケアを改善するためには、医学研究や治療における問題解決型のアプローチを根本的に変える必要があります。私たちは、従来の還元主義的なアプローチに加えて、人工知能(AI)と高度なビッグデータ解析に支えられたインタラクティブな研究を提案します。このような研究アプローチは、医療現場で日常的に収集されるデータに適用することで、Multimorbidityに関連する研究課題のための統合プラットフォームを提供します。これには、例えば、複数の相互作用因子に基づく予測、相関、分類問題などが含まれます。しかし、このようなMultimorbidity研究のパラダイムシフトのアイデアを実現するためには、電子健康データの最適化、標準化、そして最も重要なことは、国内および国際的な共通の研究インフラに統合することです。最終的には、効率的なAIアプローチ、特に深層学習を、医療従事者のワークフローの中に直接、臨床ルーチンに統合・導入することが必要です。
Keywords: multimorbidity, artificial intelligence, machine learning, population aging, chronic diseases
ここまでは仰るとおり,何も難しいことは言っていません。
ここから徐々に何言っているか分からなくなるので,ゆっくり読み解いていきます。
1. はじめに
Multimorbidity患者は、複雑なケアを必要とする。一般開業医(GP)は、これらの複数の医療提供者の異なる推奨事項や処方を統合するという厳しい任務に直面している。さらに、現在の臨床ガイドラインは疾患別に作成されており、これらの患者の意思決定をさらに複雑にしています。また、Multimorbidityの患者は通常、臨床試験から除外されているため、これらの患者に対する単一疾患の管理に関する推奨事項でさえも不確実な場合があります。また、複雑な投薬方法や情報量の多さによって、ケアの提供や患者の自己管理が制約されることもあります。いくつかの単一疾患に対して患者に与えられる推奨事項は、相互に矛盾し、利益よりもむしろ害をもたらす可能性があります。
Multimorbidityの患者すべてが同じように有害な転帰のリスクを抱えているわけではない。 Multimorbidityは、併存疾患の数だけでなく、ある特定の疾患の組み合わせにも依存することが示されています。 疾患の組み合わせには、高血圧のように集団の中で非常によく見られる疾患もあれば、蓄積される傾向のある疾患もあるため、ランダムに発生するものもあります。 しかし、疫学調査で用いられてきた、疾患のカウントに基づいた古典的な多臓器不全の測定方法は、信頼できる既往症を捉えるには十分ではないとされています。
疾患数カウントはなんだかんだ言って信頼性が高いと思っていました。
やはり特定の疾患のパターンが大事ということですね。
特定のアウトカムを予測し、個別化された治療法を決定する上で、患者を中心とした解決策という観点から、Multimorbidityの問題に適切に対処するための知識ベースは存在しない。これは、Multimorbidityの複雑性を適切に管理する方法論的枠組みが開発されていないことが原因です。複雑さの意味を明確にするために、以下の例で説明します。
Multimorbidityの方法論的枠組みこそ
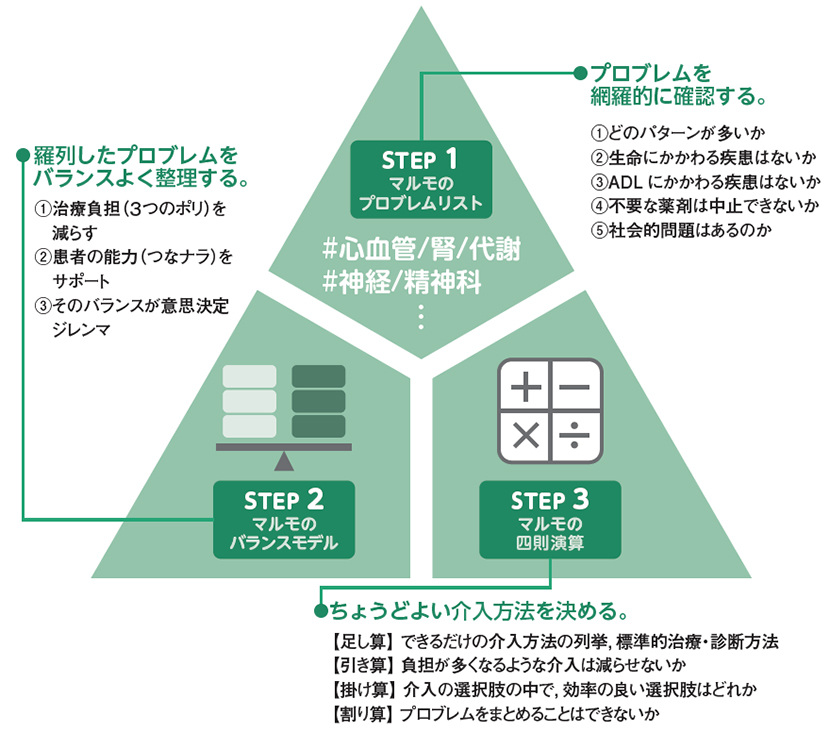
これだと思っているのですが,まだ未完成なのでもう少し修正の余地ありです。
一般的に、高齢者(60歳以上)では、慢性疾患の数が増えると、不安や抑うつなどの精神障害の有病率も高くなります。身体障害と精神障害は完全に区別されるものではなく、精神障害が心・代謝疾患や慢性疼痛疾患と関連しているなど、この2つには共通のメカニズムがあります。これらの知見の重要性は、精神障害が慢性身体疾患の経過や健康アウトカムに悪影響を及ぼすことが実証されたことにあり、プライマリーケアの場で高齢のMultimorbidity患者にこれらの障害を積極的に求めることが正当化されるかもしれない。
家庭医療の先生の書かれた論文は大変読みやすいです。BPSの考え方が必須ということです。
高齢者のMultimorbidityのもう一つの特徴は、従来の診断ラベルを超えて、高齢者の生活の質や機能的能力に悪影響を及ぼす健康状態が存在することである。その中でも、歩行障害、視力・聴力低下、バランス障害、めまい、転倒の素因、失禁、慢性疼痛、せん妄、認知障害、フレイルなどの疾患は、認知症、障害、最終的には死などの重要な有害な転帰に影響することが証明されているため、研究者の最も注目を集めています。フレイルは、複数の生理学的システムにおける恒常性維持のための予備力が低下した状態と定義され、縮小、緩慢、衰弱などの症状を呈し、多臓器不全の発症における最終的な共通経路と考えることができます。認知機能障害は、高齢者に非常に多く見られる疾患であり、心血管障害を持つ人では、特にうつ病との併存がある場合、認知症への進行が増加します。健康を阻害する効果は、フレイルと認知機能障害が共存するケースで最も高くなります。
さらっと書いていますが,とても重要なポイントです。
高齢者のマルモは,老年症候群をカバーすればシンプルな問題になります。
そして,うつ病・フレイルをカバーしないと予後不良です。
ハイリスクなのは心疾患を有する患者さんなので,このキーワードに反応する必要があります。
上述の例は、高齢者において、身体的疾患と心理的、認知的、機能的障害との間に存在する複雑な関係を示している。治療の効果をMultimorbidityの検討に含めると、複雑さの度合いはさらに大きくなります。薬物療法は、有益な効果だけでなく、特に複数の適応症に対して行われる場合、薬物と疾患の相互作用が予測できないため、逆効果になることもあります。実際、高齢者の多くの症状や機能制限は、薬理学的治療の結果である。
治療の効果を薬物療法に求めるので混乱するのだと思います。
非薬物療法や代替医療など選択肢を増やしたり,シンプルな処方を心がけて,相互作用をなるべく起こらないようにすることが重要だと思います。(特に高齢者は)
このような複雑性を理解することは困難です。というのも、Multimorbidity患者の研究は、疾患名などの明確なカテゴリーの範囲を超えて行わなければならないからです。古典的な統計手法では、これらの患者を層別化するための適切なフレームワークを提供できないため、より包括的な研究フレームワークが必要とされています。
これこそ,マルモのプロブレムリストが網羅的だと思っています。
疾患カテゴリーを極力ゆるく捉えることが大事なのでしょう。
一つ一つ見ているようで,全体像をゆったり捉えているイメージです。

こんな感じですが,ここからがこの論文の大事なところです。
その一つの可能性は,機械学習(ML)やビッグデータ(BD)技術のAIアプローチにあると思われます.これらの技術は,産業,金融,マーケティングなど,人間の活動の他の多くの分野で複雑な問題を解決するために,すでに実りある結果をもたらしています.
このレビューの目的は,データ解析に対する現在のアプローチの限界をまとめ,Multimorbidity研究における代替手法の可能性と欠点を提示することです。最近発表されたHassaineらの論文では、電子カルテ(eHR)のデータ配列に隠されたMultimorbidityパターンを特定するための方法論の進歩と、これらのパターンの時間経過を追跡する方法について、詳細な分析が行われました。それどころか、私たちの概観は、医療関係者の目にはMultimorbidity研究の問題がどのように映っているのかを示しているからです。
Hassaineらの論文はこちら。

疾患の繋がりが時間とともにどう変わるのかという解析なのですが,この辺りから私には理解不能な内容になってきました。

疾患の組み合わせをドットと色で分けると,きれいな分布になるようです。
この下の先に起こりそうな疾患予想はなんとなくイメージできました。

そこで、本稿では、医療関係者が機械学習(ML)ビッグデータ(BD)研究の本質的なアプローチについて理解を深め、これらの手法をmultimorbidity研究に広く導入する際の障壁を克服するためのヒントを提供し、医療行為の質を向上させることを最終的な目標としています。著者らは、自らの経験に基づいてこれらの問題を考察し、問題の定義からデータや手法の選択、研究結果の解釈に至るまでの複雑な問題解決プロセスにおいて、医療専門家とデータサイエンティストがより緊密に連携する必要性を強調しています。
目的はわかりましたが,この論文を最後まで読んでMultimorbidity研究に機械学習やビッグデータを入れられる自信がないです…。誰か作って欲しいです。
2. Multimorbidityの研究におけるパラダイムチェンジの必要性
医学分野の古典的な研究アプローチでは、研究課題の範囲は、明確に定義された統計的手法の範囲内で答えが得られるものに限られます。データ分析は、証明または否定されるべき明確な仮説に基づいて行われます(仮説駆動型アプローチ)。このアプローチの前提条件は,十分に文書化された知識ベースと,厳格なプロトコルに従って収集されたデータセットです。
古典的な統計学の重回帰モデル(MLR)は,モデルの構造はあらかじめ決められ固定されています.入力変数の独立性,従属変数と独立変数の間の線形性,残差の正規性(バランスのとれたデータ分布を提案する),内生(交絡)変数がないという仮定に基づいており,研究課題の範囲や分析に使用できるデータの種類を制限します。例えば、これらのモデルは、線形モデルに適合しない問題や、多数の変数を利用する問題には適していません。複雑なネットワークの中で構成要素が相互に関連しているMultimorbidityの問題に対処するには,古典的な統計手法だけでは不十分です.そのため、構成要素の数や構造だけでなく、構成要素の新たな特性が結果の重要な決定要因となる可能性があります。
Multimorbidityの研究を重回帰モデルで行うと,不確実なパラメータが多すぎて結局優位差が出ない(出たとしても真のアウトカムとは言えないもの多い)のですね。
仮に、Multimorbidityの研究における理論的なパラダイムシフトを、実用化のレベルにまで高めたいとします。この場合,医学研究における問題解決のためのアプローチを変える必要があります.
慢性疾患やMultimorbidityに関連する現象を研究する際には,今日の科学的推論を支配している古典的な還元主義的アプローチに加えて,複雑系の側面からのアプローチを補完的に用いるべきである.
還元主義のパラダイムに依拠した科学的推論では、現実世界の因果関係は、限られた論理的ルールと静的な数学モデルによって記述できるとしています。この概念は,理解すべきシステムをその構成要素に分解し,分析すべきだと仮定している.科学的な推論は,矛盾や不確実性を排除した耐久性のある論理と明確な仮説に依存している.
しかし,生物システムは複雑系のように振る舞います.複雑系では,その特性は,構成要素の相互作用を通じて現れる。これらの相互作用から生じる明確な現象としては、自発的な秩序(自己組織化)、非線形関係(一方の実体の変化が他方の実体の一定の変化に対応しない)、冗長性(複数の補完的な経路の存在)、フィードバックループ(因果関係の結論を不可能にする因果の連鎖)、高い適応性(機能性)などが挙げられる。多くの多様なモダリティが意思決定に寄与していることに常に留意することが重要である。
複雑系を考える上での特性はこの5つ
1. spontaneous order (self-organisation) それぞれが組織化
2.non-linear relationships 非線形関係
3. redundancy 複数の補完的な経路
4. feedback loops 因果の連鎖
5. high level of adaptability 適応性(機能性)
確かに一般臨床においても時間することばかりですので,マルモを理解する上でこれらの視点で分析することは診療のヒントにもなるのではないかと思います。
分子科学の研究と疫学的観察に基づいて、加齢と慢性疾患やMultimorbidityの発症を統合的に捉えることができる証拠が増えてきています。このプロセスは、慢性疾患や機能障害の蓄積のダイナミクスが時間とともに異なる、さまざまな軌道で表すことができます。軌道上でのその人の位置は、遺伝、環境、社会、生活習慣などの内的要因と外的要因の相互作用、およびそれらの時間的変化のダイナミクスに影響されます。
この考え方は,生物学的システムにおける複雑性の概念の中に位置づけることができます。それによると,加齢とは,臓器,制御システム,調節ループをつなぐ複数のコミュニケーション・チャネルが徐々に破壊され,それらの間で情報が流れるようになるプロセスです。これらのコミュニケーション・チャンネルの乱れは、身体の機能的な能力の低下と、加齢性疾患、障害、虚弱性の出現という形での表現型の分散と関連している。高齢者は、異質でありながら、重複する障害のために、互いに大きく似ています。
まさにそうなんですよね。
複雑系を扱っているのですが,実はパターンがあるということです。
ここをシンプルにしなければ,他の問題を柔軟に考えられなくなります。
複雑系の側面から科学的推論を取り入れることで、システムの構成要素間に存在する関係性に関する知識が不足しているにもかかわらず、Multimorbidityに関連する現象に関する結論を出す能力が向上することが期待されます。このタイプの思考は,結論を出す際に複数の要素を考慮し,「causality/determination因果関係/決定」ではなく「chance/probability偶然/確率」という言葉を用いて操作します。複雑な問題を解決するための方法や手法を模索する際には,異なる理論の断片,混合された方法論,学際的なアプローチを併用することができる.方法の選択は、研究者の責任の大きな部分を占めており、研究者の知識と直観に依存しています(そして、ある程度、主観的です)。
因果関係から探るのではなく,確率論を用いるというのは,実臨床でも行われていることだと思います。すべてが因果関係通り起こるわけではない領域であれば,確率論的な思考が重要になる気がします。この導入は普段のマルモのアプローチで考えていることと酷似しています。
3. 慢性疾患とMultimorbidityの研究における機械学習/ビッグデータのアプローチと課題
ここ数十年の間に、デジタル画像技術や分子生物学的診断法などの医学・医療の新技術が発明され、また、ヨーロッパをはじめとする多くの国で患者登録や電子カルテが整備されたことにより、医学研究と臨床の両方において、データの量と複雑さが急速に増加しています。そのため、古典的な研究手法では、データ解析の課題に対応できなくなってきました。AIアプローチの機械学習/ビッグデータからの手法と技術は、代替のソリューションを提供するために登場してきました(表1)。

ここを勉強しないと置いていかれそうなので,素人は少し調べておく。
Knowledge Discovery (KD):ナレッジ・ディスカバリー

ナレッジディスカバリ-プロセスとは、知識発見におけるプロセス全体をさしており、ナレッジディスカバリやデータマイニング、ナレッジクリエーションなど企業全体の情報活動を含むものとして考えられる。
http://www2.ipcku.kansai-u.ac.jp/~yada/knowledge.htm
Data Mining (DM):データマイニング
マイニングとは、鉱脈を掘り当てるという語源からきている。データマイニングとはまさに、膨大なデータの中から、ある有用なルールや規則性(鉱脈)を掘り当てるプロセスである。新しく有用なルールは、それほど簡単には生まれてこない。むしろ、金脈といっしょで、ほとんど失敗に終わるといっていいかもしれない。しかし、ここから得られるものは、将来のビジネスへの有用な示唆を与えてくれる可能性持っている。特に、顧客ベースの知識は今後のインターネットビジネスにおいて、重要な貢献をもたらすと考えられる。アソシエーションルールやディシジョンツリーなど、多くの研究者による成果があるが、適用例が非常に少なく、スキルの蓄積が求められる分野である。
http://www2.ipcku.kansai-u.ac.jp/~yada/knowledge.htm
ビジネス用語からのものしか見つけられませんでしたが,ニュアンスはむしろそちらのほうがしっくり来ました。むしろ医療に活かしていくという考え方なんでしょうね。
Machine Learning (ML):機械学習
人工知能(AI)の下位カテゴリである機械学習(ML)は、コンピュータにデータのパターンや構造を分析、解釈させ、人間が介在せずに学習、推論、判断できるようにすることに重点が置かれた計算科学分野です。わかりやすく言えば、機械学習を使用すれば、コンピュータ アルゴリズムに大量のデータを供給し、入力データのみに基づいて、コンピュータに分析させ、Data Drivenな推奨や決定を行わせることができます。修正されたデータが見つかれば、アルゴリズムはその情報を組み込んで、判断の精度を向上します。
機械学習の仕組み
機械学習は、次の3つの要素で構成されます。 まず、答えがすでにわかっているパラメータ データがモデルに入力されます。次に、アルゴリズムが実行され、アルゴリズムの出力(学習結果)が既知の回答と一致するまで調整が行われます。このとき、入力するデータの量が多くなるほど、システムは高度な計算判断を学習、処理できるようになります。
機械学習が重要である理由
データはあらゆるビジネスの原動力です。競合他社をリードするか後塵を拝するかはデータ主体の意思決定で明暗が分かれる傾向が強くなっています。機械学習は、企業データや顧客データから価値を引き出し、他社の先を行くための意思決定を導く強力な手法として活用できます。
https://www.netapp.com/ja/artificial-intelligence/what-is-machine-learning/
The Big Data analytical approach;ビッグデータ分析アプローチ
マッキンゼーレポート(Big data : The next frontier for innovation, competition, and productivity)を全部読んでみました。
というのは冗談で
とっつきやすそうなものを読んでみました。
- ■クロス集計
- ■クラスター分析
- ■アソシエーション分析
- ■ロジスティック回帰分析
- ■決定木分析
- ■主成分分析
実際にビッグデータをするには以下のツールが用いられます。
- ■BIツール
- ■データマイニングツール
これは今後の課題ですね。
一方でビッグデータに対するミニデータアプローチという論文もあり,可視化しやすくなる工夫もあるようです。
https://www.jstage.jst.go.jp/article/mii/33/1/33_1/_pdf
Precision medicine:プレシジョンメディシン
がんゲノム情報における個別化医療がよく検索で出てきました。
e Precision Medicine Japan|がんゲノム情報を用いた全国レベルでのPrecision Medicine体制の構築へ
予測的,予防的,参加型,個別の評価と治療という視点と理解しました。
The black box concept:ブラックボックスコンセプト
直感的に理解できそうな単語ですが,論文の説明がわかりやすかったです。
ブラックボックスコンセプトとは特徴の識別を容易にするために非線形変換を使用するモデルを指します。これは、人工ニューラルネットワーク(ANN)やディープラーニング(DL)と呼ばれる新しい概念などの複雑なアルゴリズムで使用されます。
論文に戻ります
この代替研究アプローチは,「知識ベースの評価」の前に「データのパターン抽出」のステップがある,データ分析の知識発見(KD)マルチステッププロトコルの一部として適用される広範な分析ツールを備えており,このデータ分析アプローチは「データ駆動型アプローチ」と呼ばれている.
この研究アプローチのアルゴリズムやツールは,数学,統計学,コンピュータサイエンスなどの異なる分析分野からまとめられており,大容量で高速な分析が必要なデータセットや,高いレベルの多様性や複雑性(高次元化,複雑な関係性など)を示すデータセットをコンピュータに分析させることができる(表2)。


ここからが,実際にやってみないとわけがわからない世界になってきました。
論文のキモなのだと思いますが,一読しただけではさっぱりです。勉強しなければ。
以下説明
ML/BDの分析アプローチは,精密医療に向けた医学・医療のパラダイムシフトに挑戦することを可能にします.
関連ルールの典型的な表現は,IF X THEN Yであり,X,Yは項目の全セットからのサブセットです.ARMは、ルールのセットとして簡単に解釈できるため、人気のあるマイニング手法です。TARは、あるアイテムのセットが、特定の時間帯に、同じトランザクション内の別のアイテムのセットと一緒に現れる傾向があることを表現している。
LRは、2つの値しか持ち得ない結果の確率をモデル化する手法です。これは、二項変数(従属変数-1/0、TRUE/FALSE、YES/NOなどでコード化されたデータを含む)と独立変数の資産との関係を記述する最適なモデルを見つけることを目的としている。
NBは,分類に必要なパラメータを推定するために,少数の学習データを必要とします.NBは,各属性が各クラスに属する確率を用いて予測を行う.NBでは,各属性があるクラス値に属する確率は,他のすべての属性から独立していると仮定することで,確率の計算を単純化している.インスタンスが各クラスに属する確率を計算し、最も確率の高いクラス値を選択して予測を行う。
DTsは、フローチャートのような木構造をしており、各非葉ノードは属性のテストを、各枝はテストの結果を、葉ノードはターゲットクラスまたはクラス分布を表しています(図1参照)。各DTsアルゴリズムは、情報利得やGinni-indexのような独自の分割基準を用いて、枝や葉を作成します。新しいレコードの場合、これは関連する条件に基づいて枝を通り、リーフ・ノードで終了し、その後はそれ以上の枝分かれはできないことになる。そして、このリーフノードでは、関連する精度などの指標を用いて、新レコードのターゲットクラスを決定します。
RF モデルは,ツリー構造の分類器の集合体で構成されている.このモデルは,学習データのランダムにサンプリングされたサブセットを含み,これらの小さなデータセットにモデルを適合させ,予測値を集約するというバギング法を用いている.バッグ外誤差は,汎化誤差の推定値として用いられる.
SVMは,各レコードをn次元空間の点としてプロットする(ここでnは入力変数の数).各変数の値は縦軸を表しています.そして,SVMは,2つの対象クラスを非常によく区別する超平面を見つけることで分類を行います(図2参照).このアルゴリズムは,学習時間が長くなるため,大規模なデータセットには適していません.
ニューラルネットワークは、生物学的なニューラルネットワークにヒントを得た計算モデルで、図3に示すように、人工ニューロンと呼ばれる単純な連結ユニットの大規模な集合体をベースにしています。決定メカニズムを知りたくない場合にこの方法を使用します。この方法はブラックボックスのように機能します。つまり、モデルがいくつかのニューロンの非線形結合であり、それぞれのニューロンが他のいくつかのニューロンの非線形結合であることはわかっていますが、各ニューロンが何をしているかを言うことは不可能に近いのです。このアプローチは、DTやSVMとは逆です。

クラスタとは,互いに似ているが,異なるクラスタに属するオブジェクトとは似ていないオブジェクトを記述したデータの集まりである(図4参照).K-meanアルゴリズムは,結果として得られるクラスター内の類似性が高く,クラスター間の類似性が低くなるように,オブジェクトの集合をk個のクラスターに分割することを目的としている.クラスタ内類似度は,クラスタ内のオブジェクト間の距離の平均値で測定され,これはクラスタの中心とみなすことができる.

KNNは一般的に、テストサンプルと指定されたトレーニングサンプルの間のユークリッド距離に基づいています。出力はクラス・メンバーシップであり,すなわち,レコードはその近傍の多数決によって分類され,レコードはk個の近傍の中で最も多いクラスに割り当てられる(図5参照).ユーザはパラメータkを指定します。

PC分析では,多変量データの次元を,情報の損失を最小限に抑えながら,2つまたは3つの主成分に削減することで,データセットを可視化することができる.これらの成分は,元の成分の線形結合に対応し,データの最大分散方向を表す.
SOMは,次元削減に用いられるNNの代表的なものである.この方法は,UNV学習に基づいて,学習サンプルの入力空間の低次元の離散化された表現を生成するものである.その表現はマップと呼ばれ,入力空間のトポロジー特性を保存するために近傍関数を使用する(図6参照).

LCAは、カテゴリカルおよび/または連続的な観測変数を用いて、被験者間の測定されていないクラスメンバーシップを特定するための統計的手法である。
グラフベースDMは、典型的には、グラフとして表現されたデータベースに適用され、データに埋め込まれたトポロジー的な部分構造を探索する。その目的は,単に構造を抽出するだけでなく,潜在的に興味深い部分構造を特定することである.
NLPは、音声やテキストのような人間の自然言語を自動的に処理し、コンピュータやロボットに人間の言語を理解する能力を与えるもので、例えば、健康記録や患者の音声に基づく病気の予測などがある。
NMFとその拡張であるNTFは、非負のデータ行列を低ランクの非負行列やテンソル(マルチウェイアレイ)の積に分解する新しい手法です。その結果は疎であり,簡単に解釈できます.
データセットに適用されるML/BD技術のアルゴリズムは,データの最適な記述をもたらしているモデルを得るために,しばしばデータ構造について学習しなければならず,古典的統計学の厳密なMLRモデルとは一線を画しています.また,ML/BD-AIの研究手法は,研究課題に手法を適応させることで,研究課題の幅を広げることができます。これにより、臨床研究を、母集団の不均一性が研究を行う上での障害とならない実世界のシナリオに近づけることができると考えられます。しかし、ML/BD-AIの研究アプローチが古典的な統計手法に比べて多臓器不全の研究に適している決定的なポイントは、このアプローチがデータ構造に関係なく、データの潜在的な空間と時間的な傾向を明らかにする能力を持っていることです。多臓器不全に関連する問題の複雑なデータ構造は、複数の疾患や原因となる要因、外部の社会人口学的要因と内部の生物学的要因、そしてそれらの間の力学を動かすメカニズムが十分に理解されていないことから生じます(表3)。

ここから急に,ピンときました。
機械学習/ビッグデータのAI研究分野の応用が
- 人口管理と予防プログラムの計画。
- 健康状態の予測と予後。
- 多剤併用および併存疾患の文脈における医薬品安全性監視。
- 健康リスクの層別化と個別化された治療。
- 患者の特徴の多様性。
- 臨床意思決定支援。
- 複数の機能に基づく結果の予測。
- ケアの質/パフォーマンスの測定。
- 複雑な問題解決タスク。
に使えるということがわかりました。
自動化のためのML手順の傾向は、分析プロセスにおける医療専門家の役割を低下させる可能性があります。しかし、それは妥当ではありません。ほとんどの医療分野の問題は困難であり,データ分析の自動化プロセスを適用するだけでは,医療専門家の指導なしには解決できないため,この役割は重要です.
これまでに実施された研究の大半は,ML/BD研究アプローチの概念の一部に直面している.例えば,大規模データセットを利用して(臨床現場で使用されているものと比較して)代替モデルを生成したり,ガイドラインの推奨事項を個別に調整したり,データソースを組み合わせて新しいバイオマーカーを発見したり,未知のメカニズムを特定したりすることが挙げられる.これらの研究は、単一疾患の研究に焦点を当てた還元主義の理論の枠内に留まっており、逆に複雑なMultimorbidityに対処するのに適した統合的なアプローチは対象外となっています。これらの研究の多くは、Multimorbidityに関連する問題を絞り込み、新たな仮説を生み出すのに有用であることが示されたが、Multimorbidityの人々を治すための効率的な予防・管理戦略を確立するために必要な、複数疾患のクラスター化に関連する問題に答えるには不十分であった。
複数の疾患を持つ患者がどのような転帰をたどるリスクがあるのか、どのような患者がどのような治療から恩恵を受けるのか、どのようなリスク因子や病態生理上の障害がどのような患者群を指すのか、患者がある軌道から別の軌道に移行するにはどのようなメカニズムがあるのか、など、開業医が回答に興味を持つような質問がありました。
最も多かったのは、がん、糖尿病、アルツハイマー型認知症など、いくつかの慢性疾患の早期診断、個別化治療、予後の予測に関する話題でした。これらの疾患は、深刻な結果をもたらすことで知られており、多くの合併症を伴うため、それだけで複雑性の高い特徴を持っています。近年、医療分野では、患者の個別化医療を実現すると考えられているハイスループット(オミクス)技術が発明され、ML/BD分析法の開発がさらに促進されています。
これですね。きっとこういう事ができるであろうなということを,見事に言い表してくれています。パターンがあるのであれば予測ができるのではないかという話ですね。
RichteraとKhoshgoftaaraは、がんのリスクと再発の予測のための現在の手法に焦点を当てたレビュー論文の中で、モデリングプロセスに関連する方法論的な懸念について論じてい。著者らは、集団レベルでのがんの予測と予後のモデル化には、臨床データ、社会データ、行動データなど、eHRや国の登録簿で広く利用できる構造化データの価値を強調しています。ゲノミクスやプロテオミクスなどの分子生物学的データは、個別化された治療法の決定に役立つ可能性がありますが、集団スクリーニングには適していません。モデルに使用される技術は、統計的手法では、cox比例ハザード回帰モデルやリスク生存分析、またはML法では、SVM、ANN、DT、RFなどがあります。しかし、ほとんどの場合、有効な予測モデルを実現するために、複数の手法を組み合わせて使用します。データアナリストは、どのタイプのモデルがどの研究問題に最適かを決定する際に、ドメインエキスパートと密接に協力する必要があります。
Kourouらは、特に癌の予測と予後にML手法を使用することに焦点を当てた論文の中で、日常的に使用できる正確な予測モデルを提供するために、SVM、DT、ANN、BNなどのMLツールの能力を強調しています。未知の入力空間から使用される新しい特徴を選択することで、これらのモデルは、がんの発症および進行に影響を与える可能性のある要因に関する知識を拡大することができます。このようにして、これらのモデルはさらなる研究を促進することができる。同様の考え方は、RajanとPrakashの研究にも見られます。彼らは、画像や検査結果ではなく、行動的・社会的な危険因子や症状の情報を用いて、肺がんの早期診断のためのANNモデルを開発し、このモデルを広く利用できるようにしました。このアプローチは、肺がんががんによる死亡原因の第1位であることを知っている実用的な観点からも価値があります。肺がんは、がんによる死亡原因の第1位ですが、血液中にバイオマーカーが存在せず、住民のスクリーニングに利用できるような簡単な方法もありません。
肺がんの早期診断モデルはできるのであれば,将来的にはMultimorbidityの予見もできるのでしょうね。
2型糖尿病の診断と進行に関連するモデル化の手順にも、同様の方法論的問題があります。Zouらは、糖尿病診断予測のための正確なMLモデルを作成するための前提条件として、データの前処理と削減方法、およびモデルの一般化方法の重要性を強調しています。研究問題を正確に定義できる医療専門家が参加しないと、モデリングの手順が、既存の知識から切り離されることなく、適用されたML法の確認的分析としてのみ機能する恐れがあります。一方,Sacchiらの研究では,慢性疾患としての糖尿病を問題にしています。糖尿病は,時間の経過とともに進行し,合併症の蓄積を伴うため,予測を行うことは困難です。この研究では、薬の処方率の経時変化の情報を時系列解析とともに用いて、糖尿病の慢性合併症の予測モデルを作成しました。糖尿病合併症の予測は、多数の変数が複雑かつ非線形な方法で相互に作用する場合、また疾患のプロセス全体を通じて、どのように困難になるかは、Yousefi L, et al.の研究で説明されています。複雑な生物学的構造と時間経過に伴う変化のダイナミクスにどのように対処するかは,興味深い問題です。この課題を解決するためには、複雑な方法とモデリング手順が必要となります。著者らは、この複雑さに対処する最善の方法は、患者をより小さな、より均質な表現型のサブグループに分けることであると述べている。そして、これらの固定された(潜在的な)表現型と、関連ルールで構成されるクラスターの時間的変化を比較した。しかし、このハイブリッド手法の結果は、現実の文脈では解釈が難しい。知識豊富な専門家の意見がなければ、このような手順は、データストリーム上での終わりのない無意味なマイニングになってしまうかもしれない。
めちゃくちゃ面白い。
疾患の予測モデルに,処方のタイミングが役立つというのは,確かにそうですね。
我々の経験則が,今後の治療に影響を与えるというわけです。
私たちの研究グループは、慢性加齢疾患に関連した複雑な臨床タスクを解決するためにML手法を適用することに長期的な経験を持っています。私たちの研究は、医学研究においては、小さなデータセットの研究を行う条件がしばしばあることを確認するものです。これは、組織レベルで研究を行う必要がある場合や、eHRが研究のためのモダリティに変化しない場合、あるいは大規模実験の複雑さと高コストによってデータセットのサイズが制約される場合に現れます。探索的研究のための理想的なプラットフォームは、調査対象となる集団のすべての特性を表している。このアプローチに沿って,小規模な研究では,参加者を複数の特徴で記述することが求められる.
我々自身の経験から、データ収集(選択)、方法の選択、結果の解釈など、データ解析の全過程において、医学専門家とデータ解析者との間の緊密な連携と良好な相互理解が必要であることを述べることができます。また、データ可視化技術によって結果の理解度を大幅に向上させることができるほとんどのタスクでは、複数の分析手法を使用する必要性があることを自信を持って述べることができます。しかし、共通の文脈の中ですべての結果を組み合わせて統合することで、関心のある問題をより包括的に把握することができます。
インフルエンザワクチン接種への反応が悪いMultimorbidityの高齢プライマリケア患者を決定する健康状態コンポーネントを発見することに焦点を当てた私たちの研究は,Multimorbidityの複雑さという問題にアプローチした先駆的な研究と考えることができます.私たちは、自分たちの仕事を通じて学ぶことで、複数の合併症を持つ高齢者の臨床的背景は、複数の関係性、非線形性、障害間の重複などの現象により高次元であり、個人を明確に分離されたグループに分けることが困難であることに気づきました。この場合、臨床エンドポイントがバイナリーラベル(病気や処置の結果が陽性か陰性か)の場合、患者の表現型決定には、ロバスト性があり、予測因子の分布や相互依存性に強い仮定を必要としない、すなわちANNなどの手法を用いる必要があります。データの高次元化は,"部分空間クラスタリング "などの部分空間解析技術のいくつかを,視覚的探索法と組み合わせて用いることで低減できる.eHRデータからの特徴抽出のための様々なDL法の構築における最近の開発は、入院患者の表現型を成功させ、古典的な特徴抽出アルゴリズムよりも優れていることを示している。これらの技術を使用する場合、解析者は複数のモデルオプションの中から選択することになるため、結果の解釈が難しい問題となる。パラメータの設定が異なると,異なるモデルセットになる可能性があります.また、様々な理由で結果が変わる可能性があるため、ドメインエキスパートは結果の信頼性について議論する必要があります。
ML/BD-AIアプローチにはデメリットもあり、これらのアプローチを用いて得られた研究結果を臨床現場に直接導入する際の障壁となっています(表4)[79,80,81,82]。

インフルエンザワクチン接種への反応が悪いMultimorbidityの高齢プライマリケア患者を決定する健康状態コンポーネントを発見することに焦点を当てた研究は後日紹介したいです。誰のためなんだという話ですが。完全に趣味です。そしてここからがクライマックスです。
4. Multimorbidity研究における機械学習・ビッグデータ解析活用の現状と今後の展望
4.1. パターンやクラスターに関連した多疾患研究の新しいアプローチ
Multimorbidity研究におけるML/BD法は,まず疫学調査において,疾患の二人組や三人組に番号をつけることで得られる大量の疾患の組み合わせを減らし,自然発生的な疾患の集まりを学習することで,調査間の疾患パターンを統一しようとする目的で用いられてきた。ロジスティック回帰分析、LCAなどの階層的クラスタリング手法、探索的因子分析など、さまざまな手法が用いられており、データソースにはeHR、国内登録、プライマリケア医によるアンケートなどが含まれています。全体的に見て,最近,比較法分析によって確認されたように,Multimorbidityのパターンは,Multimorbidityのパターンの中で頻度の高い疾患が支配的であるために,いくつかの重複が観察されるものの,疾患のスペクトル,調査対象者,分析方法によって異なり,研究デザインの標準化の必要性が示されている。本研究の結果から、併存疾患の関係を記述するためには因子分解法を用いるのがよく、深層分析を行う場合にはクラスタリング法が探索的な研究として有用であることが示唆された。ARMは、一般的に疾患の関連性を調査し、共通のパターンを探るために使用されます。ツリーベースのアプローチでは、慢性疾患や症候群の特定の組み合わせを識別できる結果が得られます。
もうサラッとすごいことを書いています。
パターン研究の標準化,クラスタリングで関係の記述,ツリーベース研究で慢性疾患や症候群の組み合わせを探るわけです。
私たちの研究グループは、パイロット探索研究において、非階層的(k-means)および階層的(LCA)クラスター分析を使用しました。その目的は、2つの主要な加齢エントロピー状態である身体的虚弱と認知機能障害のクラスター化の背後にある可能性のあるメカニズムについて、何らかの洞察を得ることでした。私たちは、まずこれらの機能障害を対象とし、慢性疾患の診断やその他の臨床的・社会的人口統計学的変数の違いを評価することで、これらの結果のリスクがある異質な患者の表現型を決定し、特定されたクラスターの説明を行いました。一方、イタリアの専門家グループは、疾患ベースのクラスター化を行い、クラスター内の個人の臨床的および機能的な状態の違いを評価することで、疾患クラスター化の根底にあるメカニズムについていくつかの洞察を得ていました。これらの著者は、「ソフトクラスタリング法」としても知られるファジーc-meansアルゴリズムをクラスタリング法として適用した。この方法は,オブジェクト(特徴や個体)間の類似性のレベルではなく,確率の分布をクラスタへのメンバーシップの割り当ての基礎として使用するため,古典的な「ハードクラスタリング法」よりもスケーラブルである。
ここ数年、DLの手法とeHRからのデータを、患者の表現型、病気の特徴の検出や分類、イベントの縦断的なシーケンスに基づく臨床結果の予測などのタスクに使用する傾向が強まっており、多臓器不全に関連するタスクの解決を改善することが期待されています。DLの多くの開発は、テキストの医療メモを含むeHRの生データまたは最小限の処理しかされていないデータに信頼性の高い概念をマッピングするために使用されている(エンベッディング技術)。例えば、Mengらは、大規模な保険請求データセットから、がん患者の治療ラインに関する情報を利用して、治療経路を特定した。これらの著者は、患者レベルの治療ラインを導出するアルゴリズムを作成し、クラスタリングやデータ可視化の手法を用いてこの情報を集約し、時間的な表現型を導出して病気の進行予測を支援した。Zhaoらは、心血管疾患のリスクがある患者の表現型のサブタイプを特定するために、eHRsデータに修正された非負のテンソル因子化アプローチ(画像分析における潜在的オブジェクト変数の発見に使用される技術)を適用した。ARMと各サブタイプの心血管疾患発症の推定リスクを組み合わせることで、著者らはこれまで知られていなかった表現型を特定することができた。Nguyenらは、病院の再入院の確率を予測するために、一連の概念として使用される病歴情報に基づいて、修正された畳み込みニューラルネットワーク(CNN)モデルを開発しました。また,Choiらは,次回以降の診察における診断と薬の処方を予測するための改良型リカレント・ニューラル・ネットワーク(RNN)モデルを開発した.これらのケーススタディは、慢性疾患の複雑さに直面することを目的としていますが、それでもMultimorbidityの複雑さにはほとんど対応していません。
具体的な研究がどんどん出ていますが,結局Multimorbidity研究としてはいまいちというところが衝撃です。
強化学習フレームワークのいくつかの技術は、eHRからの縦断的なシーケンスを使用して将来の健康状態を予測することに基づいて、疾患の悪化を最適に防ぐ可能性のある治療オプションのデータ駆動型の意思決定支援を医師に提供するために使用されている。
今日、Multimorbidityを評価する際の一般的な傾向として、疾患経路の理解を深めるために、疾患のみの表現から、疾患ラベルに加えて、投薬、検査所見、機能的健康状態などの情報を含む表現型のマルチモーダルな表現へと移行している。この課題に対応するために、新しいアルゴリズムやマトリックスが開発され、大規模かつマルチモーダルなデータセットを扱う能力が向上し、そこから隠れた情報を抽出することができるようになりました。主な革新点としては,基本的なML手法の静的な実装から確率的な実装への移行,定性的な記述的手法から定量的なテスト手法への移行,そして「ディープフェノタイピング」の開発が挙げられます。後者の用語は,複雑なデータ構造の層を越えて安定しているほど包括的な患者サブグループの特徴を確立するための努力を示しており,表現型の進行や新たな疾患の関連性の生成の間も同様である。
Multimorbidityに内在する複数の相互作用の時間的動態を示すことは、データサイエンティストにとって特別な課題です。これには、ケースコントロール分類や線形回帰分析の使用を超えた、より洗練されたアルゴリズムと多段階の分析が必要となります。このような複雑な時間的ダイナミクスを学習するための研究デザインはまだ十分に開発されておらず、教師なし学習(結果がわからない)や疾患と疾患の関係の枠組みの中で維持されています。データサイエンティストは、このような高度なデータ分析を構築する上で絶対的な権限を持っていますが、研究課題の作成に分野の知識を取り入れ、実行された分析の解釈可能性を評価しなければ、これらの革新の実生活での有用性は疑問視されます。Multimorbidityに関連する問題を検討する場合,不確実性や不完全で矛盾した知識の条件下で推論を行う必要があるかもしれない。論証理論のような伝統的なMLとは異なる手法は、そのようなタスクの学習においてより良いパフォーマンスを発揮することができる。このような新しいモデルでは、研究課題を達成するために、領域の専門家の知識が重要になるかもしれません。
4.2. 多臓器不全の研究における機械学習/ビッグデータアプローチの実装を改善する方法
以下の例では、医療分野におけるML/BD分析の本質的な可能性を明らかにしています。日常的に収集されるデータから新しい概念を見つけ出し、診断を支援したり、病気の分類を改善したりする可能性や、通常では不可能なテキストや画像などの非構造化データを使用する可能性があります。また、専門家による手作業やアドホックな入力を必要としない特徴表現である自動化も可能性の一つです。最後に、ML/BD分析は、異なるプラットフォームや医療環境のeHRを連携させることが可能です。
Liangらは、外来診療所と病院のeHRから使用される診療メモ(教師なしタスク)から一般的な概念を抽出するために、DLモデル(深層信念ネットワークの改良版)を適用して、臨床意思決定支援システムを構築しました。元のデータセットは,非構造化データ(プレーンテキストで書かれた症状や兆候)と構造化データ(検査データや社会人口統計データ)の組み合わせでした.DLモデルのネットワークを学習して,元の(生の)データから特徴を取得した後,古典的な分類モデルとしてSVMを用いて,DLモデルのネットワークパラメータ(重み)を教師ありの方法で調整した.抽出された特徴(DLモデルの隠れた層でコード化されたもの)は、目標とする結果指標に適合するようにさらにモデル化されました。抽出された特徴(DLモデルの隠れ層で符号化されたもの)は、目標とする結果指標に合うようにさらにモデル化されました。
最近の文献には、同様のプロジェクトが数多く見られます。これらのプロジェクトでは、疾患に特化した登録やeHRを利用し、時間的に連続したパターンや横断的なパターンを用いて、疾患活動の診断を支援/予測するために患者の特徴をモデル化しています。Norgeotらは、関節リウマチ患者の2つの大規模な病院登録から得られた構造化データ(投薬、検査、患者の人口統計、疾患活動を示す)をモデル化するために、縦断的な深層学習モデルを適用し、次の診察時の疾患活動を予測しました。2つの設定からモデルの性能を比較することで、ケアの質を評価し、モデルの相互運用性を評価することができます。Mount Sinaiのデータウェアハウスにある約70万件の患者記録を集約したeHRを用いて,教師なしの患者表現モデルを実行しました.このモデルは,患者が特定の疾患を発症する確率を評価することで評価された.
これらの例は、複雑で手間のかかる単一の慢性疾患の診断と予後を改善する上で、ML/BD研究アプローチの高い可能性を示しています。しかし、これらの研究のデザインは、単一の疾患を対象変数として使用していることや、疾患の発達段階の違いをより具体的に反映できるようなサブグループに患者を分割していないことから、Multimorbidityの複雑さを完全には捉えていません。
Pengらの研究のデザインは、このコンセプトに近いものとなっています。著者らは、台湾の国民健康保険研究データベースを用いて、ML(ランダムフォレスト法)累積欠損フレイルティ指標を開発し(データ駆動型アプローチ)、特徴の選択を専門家の意見に基づいて行う従来の指標(仮説駆動型アプローチ)と比較しています。この研究で興味深いのは、著者らが、古典的な統計手法である生存分析(Kaplan-Meier生存曲線とCoxモデル)を用いて、全死亡、入院、集中治療室への入室などの重要な有害アウトカムのリスクに応じて、患者をいくつかのグループに層別したことです。この研究のデザインは、生理学的なつながりの崩壊と表現型の分散による高齢者の機能的能力の後続的な低下として老化を提案する、老化の統合理論と首尾一貫しています。
この研究のアイデアと同様に、私たちの研究グループは、Multimorbidityの問題を研究する際には、多くの側面を持つ患者を記述するマルチモーダルデータが分類モデルや予測モデルの入力となるべきだと想定しています。また、アウトカム指標としては、疾患名ではなく、健康状態や機能低下の指標を用いるべきであるとしています。複雑な思考のパラダイムに沿って、この研究の著者は、新しい技術の評価よりも問題解決のタスクを優先して、十分に証明された方法を組み合わせて使用しました。
Multimorbidityの患者に対する治療法の推奨を管理することは、複雑な疾患と薬の依存関係のために難しい問題である。Zhangらは、強化学習(RL)に基づいて適切な投薬数を自動的に決定しながら、治療推奨を逐次的な意思決定プロセスに分解するアルゴリズムを提案しました。これは,推奨される治療セットにおける有害な薬物相互作用の99.8%を除去するものである。Zhengらは、患者の個人的な特性と病歴を用いて、患者の累積健康アウトカムを最適化する治療レジメンを推奨するRL処方アルゴリズムを学習した。一般に、医療分野におけるRLの応用は、主に治療法の推奨問題に焦点を当てている。しかし、実際の医療現場では、医療行為のすべてに関連する結果を特定することは非常に非現実的です。
また、複数の疾患を抱える高齢者の場合、医療リスクを予測するという問題があります。この問題は従来、多くの患者を診察し、臨床ガイドラインに精通した経験豊富な臨床医や、明確に定義されたリスク因子を用いた線形予測モデルによって解決されてきました。これらの戦略は、単一の疾患の場合には、多疾患の場合よりも適しています。Phamらは,病歴情報に基づいて病気の進行,推奨される介入,入院を予測するために,ディープ・ダイナミック・ニューラル・ネットワーク法を用いた高度な一時的アーキテクチャを発表しました.著者らは、eHRから使用される時間的シーケンスに基づいて将来のリスクを予測する際の重要な問題を解決しました。例えば、健康状態の変化の間の長期および短期の依存性、ケアのエピソードの不規則なタイミングとエピソード的な記録、および介入と疾患の進行の間の相互作用などです。このソリューションは、eHRからコード化された特徴(診断、処置、投薬)のみを使用し、単一の疾患の進行を対象としているため、Multimorbidityの複雑さを扱うにはまだ不十分です。Hassaineらの研究では、マトリックス因子分解法を用いて、病気のクラスターが時間の経過とともにどのように進行し、多疾患ネットワークを形成するかが示されました。実際の臨床的有用性を見ることは容易ではないため、結果の解釈には疑問が残る。
カタルーニャの研究グループは,プライマリ・ケア研究用情報システム(SIDIAP)のデータを用いて,プライマリ・ケアの大規模な高齢者(65歳以上)集団におけるMultimorbidityパターンの定義に取り組んでいる.プライマリーケアは、慢性疾患を持つ高齢者が定期的に受診する場所であり、健康歴やケアのさまざまな側面に関する情報がeHRで日常的に収集されているため、Multimorbidityのパターンを縦断的に分析するためのユニークなポイントとなっています。最近の横断研究(2019年)では、Multimorbidityのクラスターを特定するためにファジー・クラスター分析(個人を複数のクラスターに同時にリンクさせることができ、他のアプローチよりも臨床経験に合致している)を使用し、クラスターを特定するために多重対応分析(カテゴリー変数の場合)とk-meansクラスタリング(数値変数の場合)を組み合わせて使用した古い研究(2012年)とは異なるクラスターが得られた。この古い研究では、著者らは得られたクラスターを6年間追跡調査し、最初に定義されたクラスターは経時的な変化に対して比較的安定していることを示しました(追跡調査期間終了時にクラスターに留まっている患者の数と%で判断)。
最新の研究では、この著者グループは、Multimorbidityのパターンを特定するために、クロスセクショナルデザインとファジークラスター分析を用いて、Multimorbidityのパターンの縦断的な軌跡を隠れマルコフモデル(多臓器不全のパターン間の移行や死亡リスクをモデル化する必要がある場合に、複雑なMLや強化学習問題を解くための近似法)でモデル化し、クラスター間の移行確率と初期のクラスター確率を結びつけるためにいくつかの追加アルゴリズムを使用しました。著者らは、Cox回帰モデルを用いて多疾患パターンの5年生存率を推定しました。社会人口統計、投薬数、受診数などの追加変数を用いて、疾患クラスタリングの病態生理的背景とクラスタの時間的変遷を分析した。その結果、Multimorbidityの軌跡は時間の経過とともにおおむね安定していることがわかり、特定のMultimorbidityのパターンに対して予防策をオンタイムで講じることが可能となりました。
今回発表されたカタルーニャの研究グループの研究は、他の多くの研究グループよりも臨床的に優れており、Multimorbidityの集団管理のためのいくつかの方向性を示しています。主な不満点は、フレイル(虚弱)などの機能的障害が分析に含まれていないことであるが、フレイルの状態によって病気の現れ方や死亡リスクが大きく変わることが知られている。さらに、我々の研究で示したように、臨床検査や体型測定の情報は、慢性疾患が進行性であることから、疾患の重症度を層別化するための追加情報となる可能性があります。
慢性疾患の数や種類が、時間の経過や年齢の上昇に伴い、身体機能や総合機能のレベルに影響を与えることは、StenholmらやVetranoらの研究で示されています。高齢者の機能低下に伴う疾患群の時間的推移を、複数の疾患を併存させてモデル化することは、Multimorbidityの複雑性をモデル化する上でのさらなる課題である。
上述の研究は、Multimorbidityに関する実際の研究に負担をかけるいくつかの不可解な状況を明らかにした。この問題には、臨床科学的な視点とデータ科学的な視点があります。臨床面では、Multimorbidityの定義に関するコンセンサスが得られていないこと、およびクラスターを形成するために使用される疾患(またはその他の障害)の範囲が多様であることが大きな問題となっています。クラスターの同定方法が不均質であることは、さまざまな研究で見られるMultimorbidityのパターンのばらつきにさらに貢献している。Multimorbidityパターンの時間的変遷に関する研究はわずかしかなく、今後の研究デザインの指針としては不十分である。
データサイエンスの面では,モデリング性能が向上し続けているML/BDアルゴリズムが急速に進歩していることに問題があり,これが研究の比較を非常に困難にし,研究成果の実施をさらに遅らせる原因となっています.さらに,データセットのばらつきや,同じタスクの分析に利用できるさまざまなML/BD手法によって,結果にばらつきが生じる可能性があり,研究者は複数の手法を同時に適用してその効率を比較することが多い.研究にとって間違いなく有益であるにもかかわらず、eHRから日常的に収集されたデータは、主に管理や臨床試験の目的で確立されたものであり、これらのデータは提案されている研究には潜在的に不十分である。また、eHRからのデータには、データの不完全性、不規則なサンプリング、データの不均衡などの欠点があり、医学的分類や診断テストのための機械学習アルゴリズムの評価には、別の方法が必要である。データサイエンティストは,これらの欠点を克服するために,様々な前処理や次元削減の手法やアプローチを開発している.複雑なタスクを解決するために,データサイエンティストは複数の手法を組み合わせて使用したり,複雑なプロトコルを作成したりしますが,それらは互いに非効率なものです。手作業を減らすことを目的とした分析プロセスの絶対的な自動化の傾向がありますが,データ分析のすべての段階でドメイン・エキスパートの影響力がなければ,得られる結果は複雑すぎて不可解であり,実際には役に立たないかもしれません.
このような問題を解決するためには,医学の専門家だけでなく,データサイエンティストやAIの専門家が,それぞれの立場で物事を前進させるためのコンセンサスグループを形成する必要があります。これらの専門家グループは、学際的なチームで協力することで、臨床ガイドラインの作成プロセスのように、手法の検証と標準化、共通の研究プロトコルの確立を促進することができる。医療専門家が明確に定義された研究課題や目標とする成果のリストを作成することは、患者のリスクグループを特定し、電子カルテのデータをモデル化し、最も適切なケアプランを作成するための前提条件となります。プライマリーケアにおいて、高齢で複数の疾患を持つ患者のリスクを評価するための効率的で時間のかからないプロセスが確立され、継続的に改善されていけば、集団健康管理は現在よりも意味のあるものになるでしょう。このプロセスにより有能に参加するためには、医師、特に、多臓器不全患者に最初に遭遇し、プライマリ・ケア医のeHRでのデータ収集に最大の責任を持つ一般開業医は、ML/BD技術の能力とデータ分析のための定量的手法について、より多くのトレーニングを受けるべきである。
圧倒されて疲れました。
一つ一つが大事な研究だと思います。
全体像を俯瞰できたのであえて全文紹介しました。
この結論が,まさにまとめになっています。
5. 結論
高齢者(60歳以上)に対する集団ベースの健康管理は不十分である。これは主に、個別化されたケアや予防的介入の提供が、従来の研究デザインやデータ分析方法の不備によって制限されているためである。このような人口の多い層は、慢性疾患が複雑化し、Multimorbidity(同一人物に2つ以上の慢性疾患があること)が特徴です。ML/BD法に基づく代替研究手法は、Multimorbidityに伴う問題に対処するための高い可能性を秘めた真の代替手段として登場しました。これらの問題には、例えば、患者の表現型や、個人間で重複する複数の相互に関連する形質のモデル化に基づくリスク層別化などがあります。さらに、集団における慢性的な健康状態のパターンを特定することや、複数の健康状態を持つ人の健康状態が時間の経過とともに悪化していく様子を追跡することもできます。このような研究手法を日常的な臨床現場に導入するためには、医療専門家とデータサイエンティスト、AI研究者、IT専門家との連携を強化し、実社会で検証された共通の研究プロトコルを導入し、真の意味での学際的な知識ベースを構築することが課題となります。このようにして構築された知識ベースは、臨床現場で生じる様々な問題を解決するケーススタディで構成されており、将来的には学際的な視点に基づいたMultimorbidity管理に関する新たなガイドラインや推奨事項を策定することが可能となります。
Multimorbidityのケーススタディをまとめることで,新たなガイドラインが生まれる。
自分が頑張っていることがなにか医学の役に立つのではないかと勇気づけられました。
宣伝ですが,そんなカンファレンスや,ケーススタディーをまとめた連載があります。
どうぞご覧ください。(これが言いたかっただけ)