Detecting signals of detrimental prescribing cascades from social media
Artif Intell Med. 2016 Jul;71:43-56. doi: 10.1016/j.artmed.2016.06.002.
PMID: 27506130
先日,処方カスケードのブログを書きました
個人的な勉強のためにまとめたものでしたが,多くの方にご覧いただけました。
久しぶりの投稿だったので,反響がありホッとしています。

Twitterでは勉強になるコメントをいただけました。ありがとうございます。
しっかり本文を読まれなければこのコメントはできないと思います。
むー、クエチアピンと関節炎は到底思いつきませぬ🤔
— KANTA (@KANTA901619361) 2021年6月26日
処方カスケードは深い・・ https://t.co/WrvA29P1go
関節炎のところがうまくつながりませんがどういう機序なんでしょうね。。
— マッドドクター (@4De3XgP5OF44GMO) 2021年6月26日
いつも勉強させて頂いてます😅https://t.co/ZGH7f2kZp3で検索したら関節痛はcommonに入っていたので、意外とあるあるな副作用なのかもしれないと思いました💦筋骨格系の訴えにアンテナ張るようにします。 pic.twitter.com/ECDYObUSfk
— KANTA (@KANTA901619361) 2021年6月26日
確かにクエチアピンと関節痛がなぜ関係しているのかわかりません。

私が翻訳を間違えたわけではなさそうですが,Uncommonでした。

引用:Quetiapine Side Effects: Common, Severe, Long Term - Drugs.com
今回のテーマは,【クエチアピンでなぜ関節痛が起こるのか】にしたかったのですが,実は,結論から申しますとよくわかりませんでした。
しかし,その元論文をたどるとその内容がとても興味深かったので,どういう研究であるのかをシェアしたかったので珍しくブログを頻繁に更新することにしました。
まず,クエチアピンが関節炎をきたす根拠となった引用文献を紹介します。
Detecting signals of detrimental prescribing cascades from social media
Artif Intell Med. 2016 Jul;71:43-56. doi: 10.1016/j.artmed.2016.06.002.
PMID: 27506130
タイトルからして既に興味深いです。
【ソーシャルメディアから有害な処方カスケードのシグナルを検出する】
なんだか今風というか,どんな研究なのかそそられますね。
ハイライト
- 処方カスケードは、副作用と関連している可能性があります。
- 有害な処方カスケードのタイムリーな検出が不可欠です。
- ソーシャルメディアは、有害な処方カスケードを検出するための有望な情報源です。
- シーケンスマイニングは、ソーシャルメディアからの有害な処方カスケードを通知するために使用されます。
動機:処方カスケード(Prescribing Cascade: PC)とは,医薬品の副作用(ADR)が新たな病状と誤解され,治療のためにさらに処方されることをいう。しかし,このような追加処方は,既存の症状を悪化させたり,新たな副作用を引き起こす可能性がある。薬剤性副作用は入院や死亡の主要な原因の一つであるため、有害PCの早期発見と予防は重要である。有害PCを特定することで、警告や禁忌を広めることができ、未知の薬害の発見にも役立ちます。しかし、PCの検出は困難であり、これまでは行政の医療費請求データを用いた症例報告や症例評価に限られていました。ソーシャルメディアは、治療や薬害に関する議論が公開されていることから、有害PCのシグナルを検出するための有望な情報源である。
目的:ソーシャルメディアから有害PCを検出する可能性について検討する.
方法:ソーシャルメディアにはデータの不確実性とデータの希少性があるため、検出は困難である。本論文では,データの不確実性とデータの希少性を考慮し,有害な PC を示唆する薬剤と AE のシーケンスをマイニングするフレームワークを提案する.
結果:TwitterとPatient health forumから収集した2つの実世界のデータセットで実験を行った。我々のフレームワークは、既知の有害 PC に対する検証(F1=78%(Twitter)、68%(Patient))、および未知の潜在的有害 PC の検出(Precision@50=72%、NDCG@50=95%(Twitter)、Precision@50=86%、NDCG@50=98%(Patient))において、有望な結果を得た。さらに、このフレームワークは効率的であり、大規模なデータセットにも拡張可能である。
結論:本研究は、薬剤師の推測を減らすために、ソーシャルメディアから有害なPCの仮説を生成することが可能であることを示している。
ソーシャルメディアを検索する研究は他にもありました。
- Utility of social media and crowd-intelligence data for pharmacovigilance: a scoping review.
BMC Med Inform Decis Mak. 2018 Jun 14;18(1):38. doi: 10.1186/s12911-018-0621-y.PMID: 29898743


これは健康食品の有害事象についての検索をテーマにされています。
やはりTwitter強しですね。
The usefulness of listening social media for pharmacovigilance purposes: a systematic review.
処方カスケードをどうやって検出するのかというスコーピングレビューも勉強になります。
What Is Known About Preventing, Detecting, and Reversing Prescribing Cascades: A Scoping Review.

Social media and pharmacovigilance: A review of the opportunities and challenges.





1. はじめに
医薬品に関連する副作用(Adverse Effects: AE)は,米国では死亡原因の上位(年間10万人),入院原因の5%を占め,推定医療費は750億ドルに上る.しかし,医薬品の AE の中には,新たな病状と誤解され,その AE を治療するために追加の医薬品を使用することになるものがある.このプロセスは,処方カスケード(PC)と呼ばれています.図1Bに,PCのよく知られた例を示します.この例では,PC は,薬剤 d1=「ナプロキセン」を服用し,d1 によって引き起こされる AE s1=「高血圧」に悩まされた後,s1 を別の薬剤 d2=「ラミプリル」で治療するという,薬剤と AE のシーケンスである.追加の治療d2は,患者に追加のAEのリスクを負わせ,また,既存の症状を悪化させる可能性がある。その結果,PCに関連するAEはコストがかかり,管理も困難になる。我々は,有害な処方カスケード(detrimental prescribing cascade: DPC)を,後続のAEに関連するPCと定義した.図1Bでは,ある患者がPCであるNaproxen→hypertension→Ramiprilを使用した結果,AE s2=「胸の痛み」に悩まされる可能性がある.DPCをタイムリーに発見することは,健康やコストへの影響を最小限に抑えるために不可欠です。特に、DPCを特定することで、禁忌や警告を発することができ、未知の薬害を発見することができます。先ほどのDPCの例では,ADRであるNaproxen→高血圧の後に「ラミプリル」を服用すると,AEである「胸痛」が発生する可能性があるため,服用してはいけないというものでした。

また,s2 は d2 に起因する未知の AE,あるいは d1 と d2 の間の薬物-薬物相互作用 の可能性もあり,専門家による検討が必要であろう.また,s2 は d2 に起因する未知の AE,あるいは d1 と d2 の間の薬物-薬物相互作用 である可能性があり,専門家による調査の対象となるかもしれない.先のDPCの例では,Drugs.comによると,s2=「胸痛」はd2=「ラミプリル」の既知のAEである(http://www.drugs.com/sfx/ramipril-side-effects.html)。これまでの研究では,PC の発見のみに焦点を当てていましたが,Caughey らのみが DPC の発見を試みました。それにもかかわらず、従来の情報源や既存のアプローチでは、DPCの検出は困難です。これまでは,自発的な症例報告が主な情報源となっていましたが,医薬品のAEの推定過少報告率は90%以上であることが示されています.最近では,行政機関の請求データベースが利用されているが,そのアプローチは,DPC をケースバイケースで調査することに限定されている.また,ADRや薬物相互作用の検出には,電子カルテの活用が進んでいます。しかし,行政請求データベースや電子カルテは,包括的な情報源ではあるものの,一般には公開されていません。したがって、ここでの重要な研究上のギャップは次のとおりです。公開されたデータソースから、調査対象となるDPCの仮説を自動的に生成することができるか?
ソーシャルメディアは,DPCのシグナルを検出するための有望なデータソースです。米国では,1100万人が健康や治療に関する情報をソーシャルメディアに投稿していると推定されています。最近の研究では,オンラインの健康フォーラム(DailyStrength,HealthBoardsなど)や一般的なソーシャルネットワーク(Twitter)でも,このような議論が可能であることが示されています。図1Aは,前述のDPCについてつぶやいているユーザーを示しています.興味深いことに,ある分析では,患者は医薬品のAEを医療専門家に報告する前にソーシャルメディアで議論する傾向があることが明らかになった.議論されたAEの中には,未知のものもあり,専門家の調査対象として興味深いものもありました.さらに,制約の多い従来の情報源とは異なり,ソーシャルメディア上のコンテンツは公開されているため,世界中のDPCを検出することができます.
本論文では,ソーシャルメディアからDPCを検出することの実現可能性を検討しています.これまでの研究では,ADR,医薬品ラベルの変更,薬物乱用,疫病の検出にソーシャルメディアを利用してきましたが,我々の知る限り,ソーシャルメディアからDPCを検出しようとしたものはありませんでした.私たちの研究では,より厳密で費用のかかる研究で検証可能な仮説を生成することで,薬剤師の当て推量を減らしています.ソーシャルメディアに投稿されたユーザと,ベンチマークとなる薬剤とAEが与えられた場合,信頼できる証拠を用いてDPCを示唆する薬剤とAEのシーケンスを抽出することを目的としています.
調べてみると、DPC検出のためのソーシャルメディアデータには、「データの不確実性」と「データの希少性」という2つの本質的な特徴があることがわかりました。構造化されていないソーシャルメディアの投稿には文脈がなく、混乱しているため、データには2種類の不確実性が存在します。存在の不確実性とは,言及された薬物やAEが本当にユーザーに摂取されているか,あるいは被害を受けているかということです。図1A の#4 の投稿では,ユーザは実際に苦しんでいることを示さずに「高血圧」と言及している.順番の不確実性とは,実際に消費された医薬品や被害を受けた AE の順番が不明であることである.図1Aでは、「ラミプリル」の前後に「高血圧」が記載されているため、「ラミプリル」と「高血圧」の実際の出現順序が不明である。実際には,存在の不確実性や投稿の時間的証拠の少なさから,薬物摂取やAE罹患の実際の時間を特定することは困難である.また,ソーシャルメディアでは,各ユーザが全く異なる薬物やAEを摂取したり苦しんだりする可能性があるため,DPCはまれです。我々の実験によると,DPC は 10 万人のユーザーのうち 10 人以下しか発生しないことが多い.
ソーシャルメディアにおけるデータの不確実性とデータの希少性のため、DPCのマイニングは困難です。まず、データの不確実性とデータの稀少性により、裏付けとなる証拠が少ないため、信頼できるDPCを選択することが困難になります。さらに,不確実性と希少性は,DPCをスケーラブルに検出するための課題となります。図2は,薬剤とAEの存在確率と順序確率を持つ2人のユーザのデータベースの例です。不確実なデータベースは,多数の異なる可能性のある世界に対応している可能性があり,各可能性のある世界は,すべての不確実なデータ項目の選択肢のユニークな組み合わせであり,異なる確率で存在しています.例えば,図 2 の不確実なデータベースは,10 個の異なる可能性のある世界に対応しており,それぞれの可能性のある世界は,薬剤,AE,注文の組み合わせが一意に決まっている.しかし,可能性のある世界の数は,不確実な値の数に対して指数関数的に増加します.薬剤とAEの総数をnとすると、存在の不確実性のみを考慮した場合、少なくとも2n個の可能世界が存在する。図 2 のデータベースでは,n = 3 であり,可能世界の数は 10 > 23 である.また,順序の不確実性があるため,異なる確率で薬とAEのすべての可能な組み合わせを考慮する必要があるかもしれません.例えば,薬が 1400 種類,AE が 6100 種類のベンチマークセットを考えてみましょう.最悪の場合,薬物と AE の順列としての DPC の探索空間は,(1400 × 6100)2 となります.さらに悪いことに,DPC はまれであるため,探索空間から刈り取ることのできる配列は非常に少なくなります.我々の実験によると,不確実なデータに対する一般的なシーケンスマイニングアルゴリズムを用いて,10万人のユーザーのデータセットからDPCをマイニングするには,1日以上かかることが分かりました.

Twitterはデータの不確実性とデータの希少性があり,そこから有害な処方カスケード(detrimental prescribing cascade: DPC)と呼ばれるものと断定するのは極めて難しいわけですね。
しかし,DPCを検出する最新の手法は,我々の問題には適応していません.まず,この手法は,症例報告から抽出されたDPCシグナルや,研究薬剤師が手動で推定したDPCシグナルの統計的有意性を調べることに重点を置いています.一方、我々の目的は、DPCシグナルを自動的に生成してから、その統計的有意性を調査することです。また、この手法で使用されている統計的有意性の指標である配列比には、データの不確実性が考慮されていません。
その結果、図3に示すように、ソーシャルメディアからDPCの信号を検出するフレームワークを開発し、上記の課題に取り組んでいます。このフレームワークは、2つの主要なコンポーネントから構成されています。まず,ソーシャルメディアの投稿から不確実なデータベースを構築するために,既存の技術を採用します(医薬品,AEの認識,データの不確実性の推定など)。次に,この不確実なデータベースをもとに,Generalized Sequential Pattern(GSP)マイニングアルゴリズムに基づいて,対象となるDPCを特定し,優先順位をつけるための候補生成・テスト手法を設計します.特に,データの希少性を考慮したDPCの選択基準を策定し,最新の確率論的手法を拡張して,あるシーケンスが基準を満たす可能性を判定します.さらに,このような基準に含まれる特性を利用して探索空間をプルーニングすることで,効率を100倍以上向上させることができました.既知のDPCを用いた検証により,本手法がDPCを検出できることが実証された(TwitterデータセットではF1 = 78%,Patientデータセットでは68%).さらに,本手法は未知の潜在的DPCの検出においても有望な結果を得ている(TwitterデータセットではPrecision@50=72%,NDCG@50=95%,PatientデータセットではPrecision=86%,NDCG@50=98%).これらのデータセット、ソースコード、評価結果は、http://nugget.unisa.edu.au/PCSocialMedia/にて公開しています。

ここでデータセット,ソースコードを公開されているようですが,とてもみる気が起きませんでした…。
2. 方法
図3に我々のフレームワークを示す。まず、与えられたユーザーとその投稿から、不確実なデータベースを構築する方法を説明します。次に,DPC を選択するための基準を定式化し,不確実なデータベースから DPC をマイニングするためのアルゴリズムを示します.
2.1. 不確実なデータベースの構築
2.1.1.不確実なデータベースを構築するための最初のステップは,各ユーザが服用する可能性のある薬剤とAEを認識することである。例えば,図1Aのユーザは,「ナプロキセン」と「ラミプリル」を服用し,「高血圧」と「胸痛」に悩まされている可能性があります。薬物とAEを認識するためには,ベンチマークとなる薬物とAEのセットが必要である。我々は,SIDER 2 から,1430個の薬剤と6155個のAEのセットを収集した.各薬剤には,ID(例:5002),一般名(例:"Quetiapine"),商品名(例:"Seroquel")がある.各 AE には,ID(例:C0027497)と複数の名称(「nausea」,「nauseous」など)が設定されている。
ここにクエチアピンが登場!このためだけにこの論文を読んでいると思うと,論文サーフィンって怖いなと思います。
辞書検索を用いて,各投稿における薬剤やAEの言及を探し出した.この設計上の決定には2つの理由があります。まず,アノテーションの取得には費用がかかるため,本研究では利用できません.第2に,辞書検索を使用することで,薬物とAEの言及をSIDER 2の対応するIDにマッピングすることができます.このようなマッピングは,後の段階で潜在的なDPCをマイニングするために,SIDER 2における薬剤とAEのADRおよび治療関係を利用するために必要となります。具体的には,まず,TweetNLP(ツイートのみ)とLingpipe(http://alias-i.com/lingpipe/)(その他の投稿)を用いて,投稿を文に分割します。各文では、ストップワードを除去しています。ツイートについては、URLと@で始まるトークンを削除し、ハッシュタグは残します
ここからは少し省略していきます。
なぜかというと,こんな式とか



こんなのが出てきて,わけがわからなくなったからです。
要は,Twitterにクエチアピンと関節痛と書いてある投稿があったので抽出して,その妥当性が計算上認められたからピックアップしたという理屈なのかもしれません(そんな単純なものではないでしょうが)
これで諦めずに,要はなにか患者さんに役に立てばいわけです。
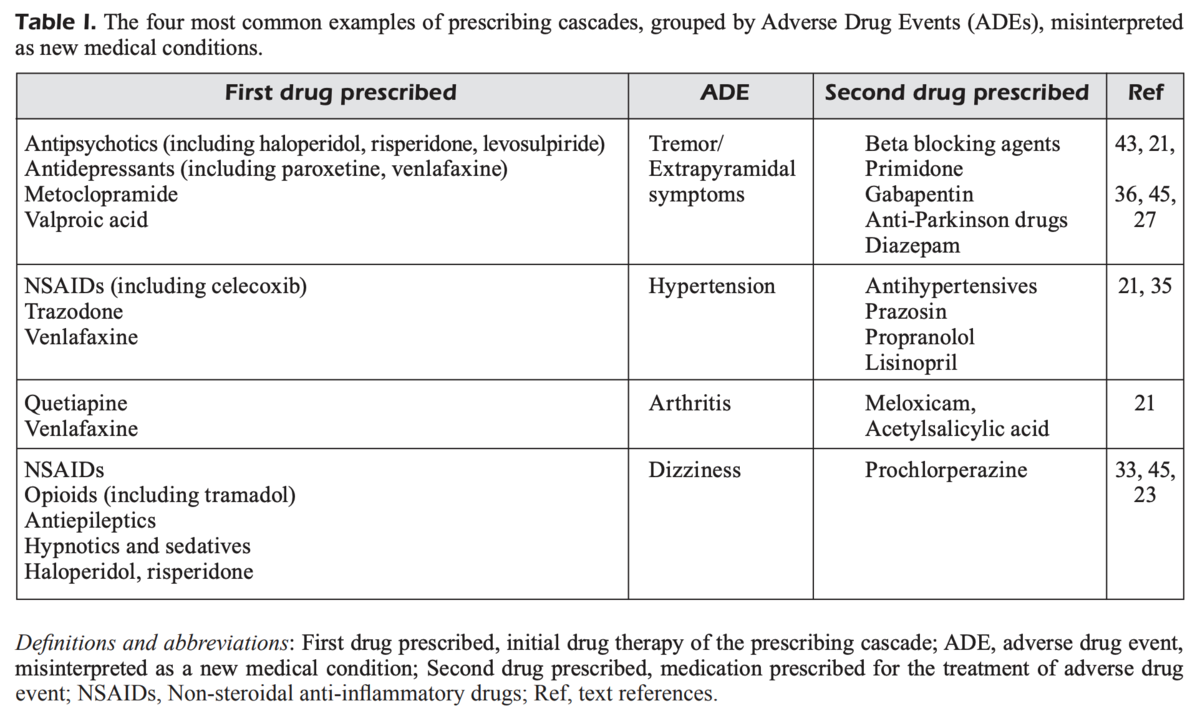
この表から得られるものがないかまとめてみます。




要は,NSAID→高血圧→降圧薬,ACE阻害薬→咳→コデインってことです。

薬剤性の肺塞栓→ワーファリンなども確かにカスケードですね。

処方カスケードをまとめたくなった時に,これをまとめてみようと思います。
そんな日は来るのだろうか。

